At Buffer we utilize the vast amount of data we have from users’ posting histories to calculate the best time to post on each major platform. In this post we’ll take a deeper look at the methodology we use to come up those best times to post.
We’ll use Instagram as an example, as it’s our most popular channel and includes a lot of rich data.
Data Collection
The first thing we’ll do is collect data from all Instagram posts shared in 2025 with the following SQL query.
We’ve made the decision internally to start with posts from channels with an American timezone, but over time we will calculate best times to post for other regions. Most of our users are based in a US timezone, and we have a suspicion that many other channels post when American audiences are online.
I should mention that we define a post’s engagement rate as the total number of interactions it receives (likes, comments, shares) divided by the number of impressions it receives.
Code
# write sql querysql <-" select up.id as update_id , up.profile_id , up.sent_at , datetime(up.sent_at, ch.timezone) as local_time , up.likes , up.comments , up.shares , up.saves , up.reach , json_extract_scalar(channel_data, '$.instagram.post_type') as post_type , json_extract_scalar(channel_data, '$.instagram.scheduling_type') as schedule_type , up.engagements , up.impressions , up.engagement_rate , ch.timezone from dbt_buffer.publish_updates as up inner join dbt_buffer.core_channels as ch on ch.id = up.profile_id and ch.is_deleted is not true where up.profile_service = 'instagram' and up.created_at >= '2025-01-01' and up.engagements is not null and up.engagements > 0 and up.reach > 0 and ch.timezone like 'America%'"# get data from BigQueryig <-bq_query(sql = sql)# set engagement rateig <- ig %>%filter(post_type %in%c("post", "reels", NA)) %>%mutate(engagement_rate = (likes + comments + shares) / reach *100)
This query returns approximately 3.1 million posts from 106K distinct Instagram profiles.
Exploratory Analysis
Let’s start by calculating a few summary statistics.
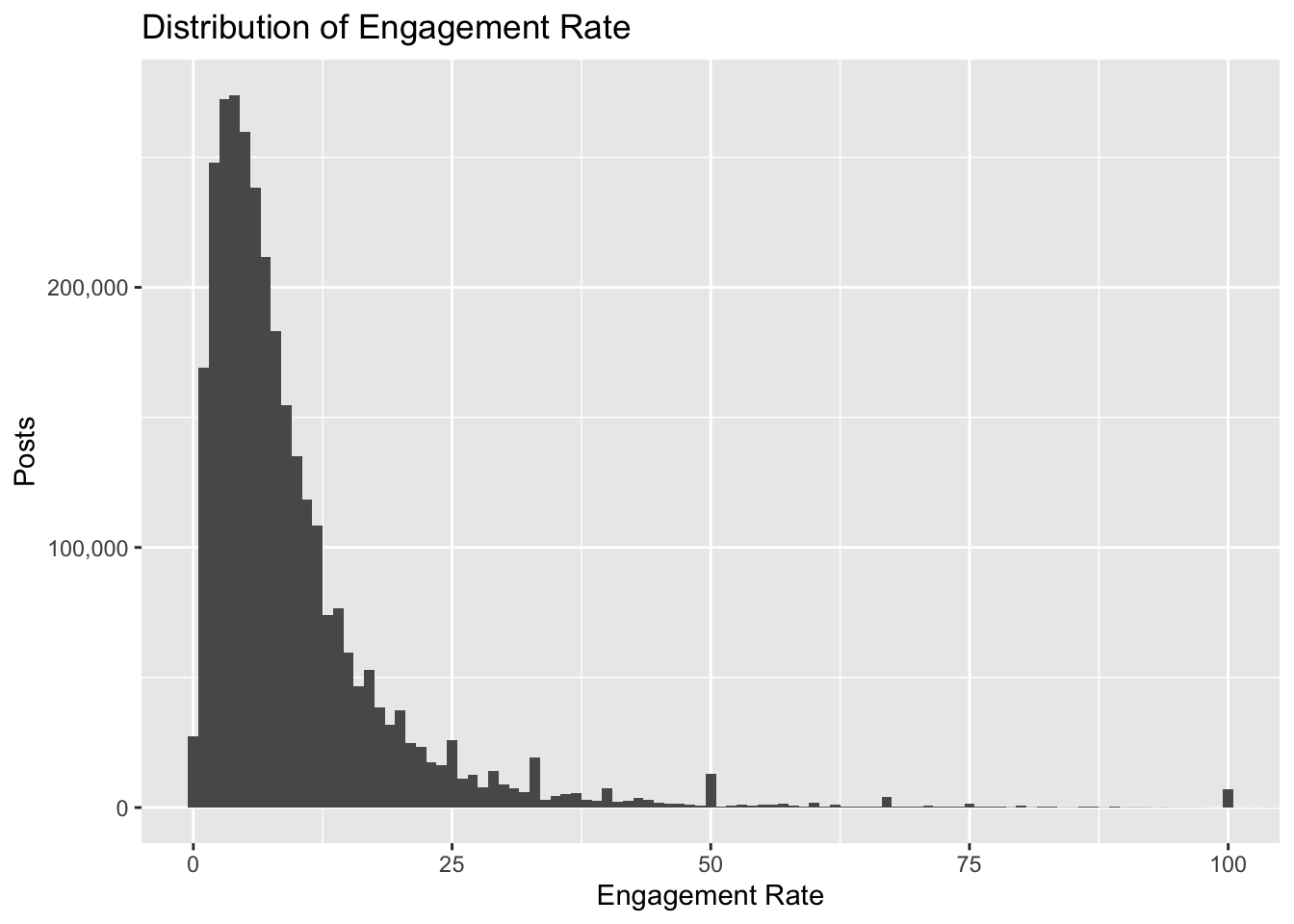
The average engagement rate is 12%, the median is 6.8%, and the standard deviation is 132%. This suggests that the variance in the data is very high. We can look at the quantiles for engagement rate to confirm this.
The maximum engagement rate is over 145 thousand percent! If we plot the distribution we can see that the data is skewed, with most posts having a relatively low level of engagement and fewer posts having high engagement rates.
Code
# plot distribution of engagement rateig %>%ggplot(aes(x = engagement_rate)) +geom_histogram(binwidth =1) +coord_cartesian(xlim =c(0, 100)) +scale_y_continuous(labels = comma) +labs(x ="Engagement Rate", y ="Posts",title ="Distribution of Engagement Rate")
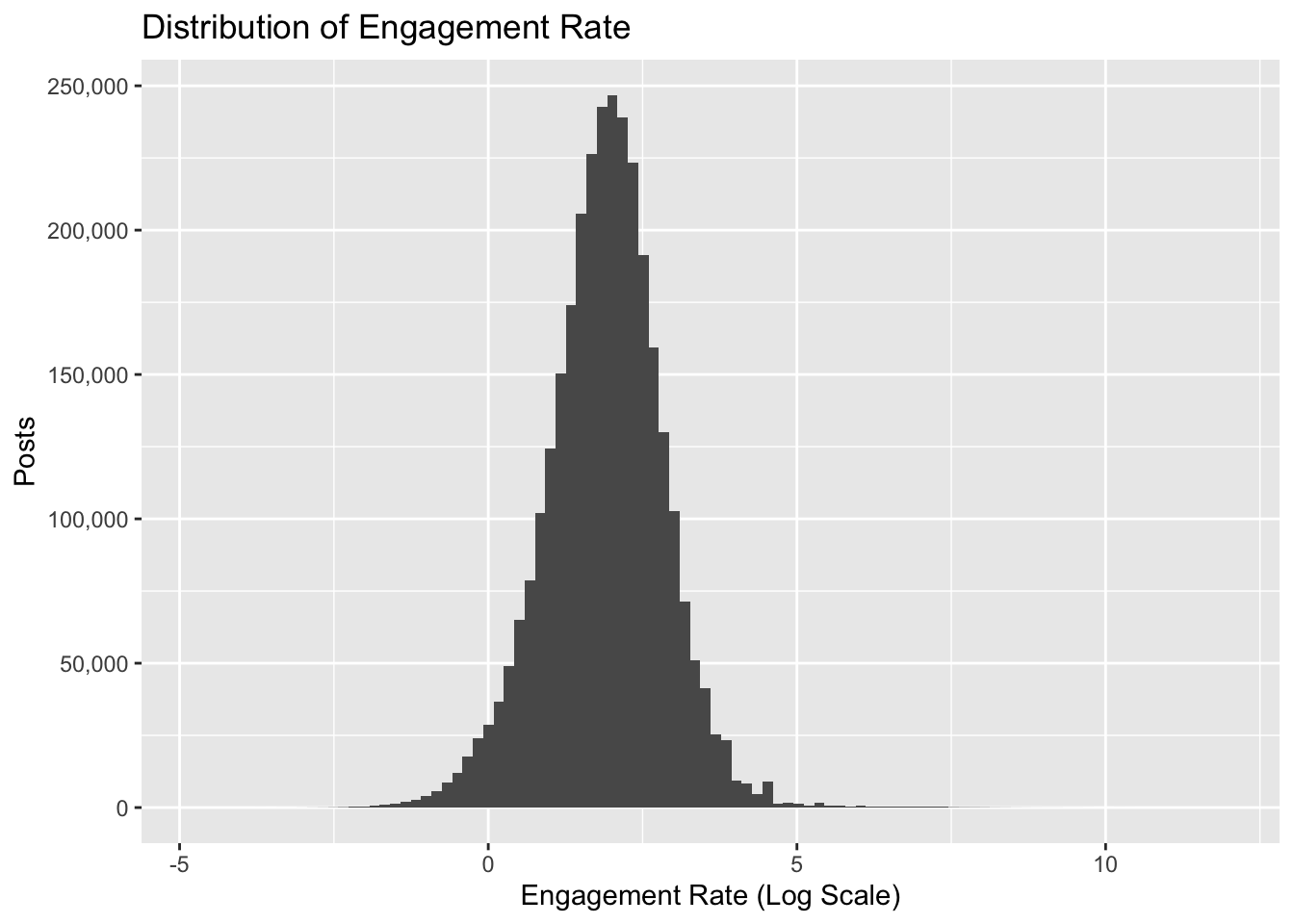
Because the data is so skewed, it could be useful to apply a log transformation.
Code
# plot distribution of the log engagement rateig %>%ggplot(aes(x =log(engagement_rate))) +geom_histogram(bins =100) +scale_y_continuous(labels = comma) +labs(x ="Engagement Rate (Log Scale)", y ="Posts",title ="Distribution of Engagement Rate")
This distribution is more Gaussian and should be better suited for the use of summary statistics
Controlling for Differences in Profiles
One issue with using summary statistics from the entire pool of posts is that certain profiles tend to have a disproportionate influence on summary statistics. Profiles with a high number of followers and high engagement tend to dominate and can seriously skew the data.
The key idea behind our preferred approach is that we shouldn’t be comparing raw engagement numbers across different users, since those numbers can vary greatly based on factors like follower counts, content quality, and difference audience types. Instead, we wanted to understand how different posting times affect each individual profile’s engagement relative to their own baseline.
Our solution begins by calculating each profile’s engagement baseline by averaging the engagement rates of all of their posts in the dataset. This gives us their typical performance level. Next, we examine how each individual post performs compared to that average. For instance, if a profile typically gets 10% engagement but a particular Tuesday afternoon post gets 15% engagement, we know that time slot helped them perform 50% better than usual.
We then convert these relative performance differences into standardized scores called z-scores. A z-score tells us how many standard deviations above or below average a particular post performed for that specific user. This transformation is crucial because it makes performance comparable across users with vastly different baseline engagement levels. A z-score of +1.0 means “one standard deviation better than typical” whether we’re talking about a user who usually gets 5% engagement or 50% engagement.
Finally, for each day and hour combination, we take the median of all these normalized scores from different users. The median is particularly important here because it controls for outliers and gives us the typical experience rather than being skewed by a few posts with exceptionally high engagement.
Let’s calculate those z-scores now.
Code
# calculate averages for profilesby_profile <- ig %>%group_by(profile_id) %>%summarise(avg_eng_rate =mean(engagement_rate),sd_eng_rate =sd(engagement_rate)) %>%filter(!is.na(avg_eng_rate) &!is.na(sd_eng_rate))# join to original dataset and calculate z_score for each postz_scores <- ig %>%inner_join(by_profile, by ="profile_id") %>%mutate(z_score = (engagement_rate - avg_eng_rate) / sd_eng_rate)
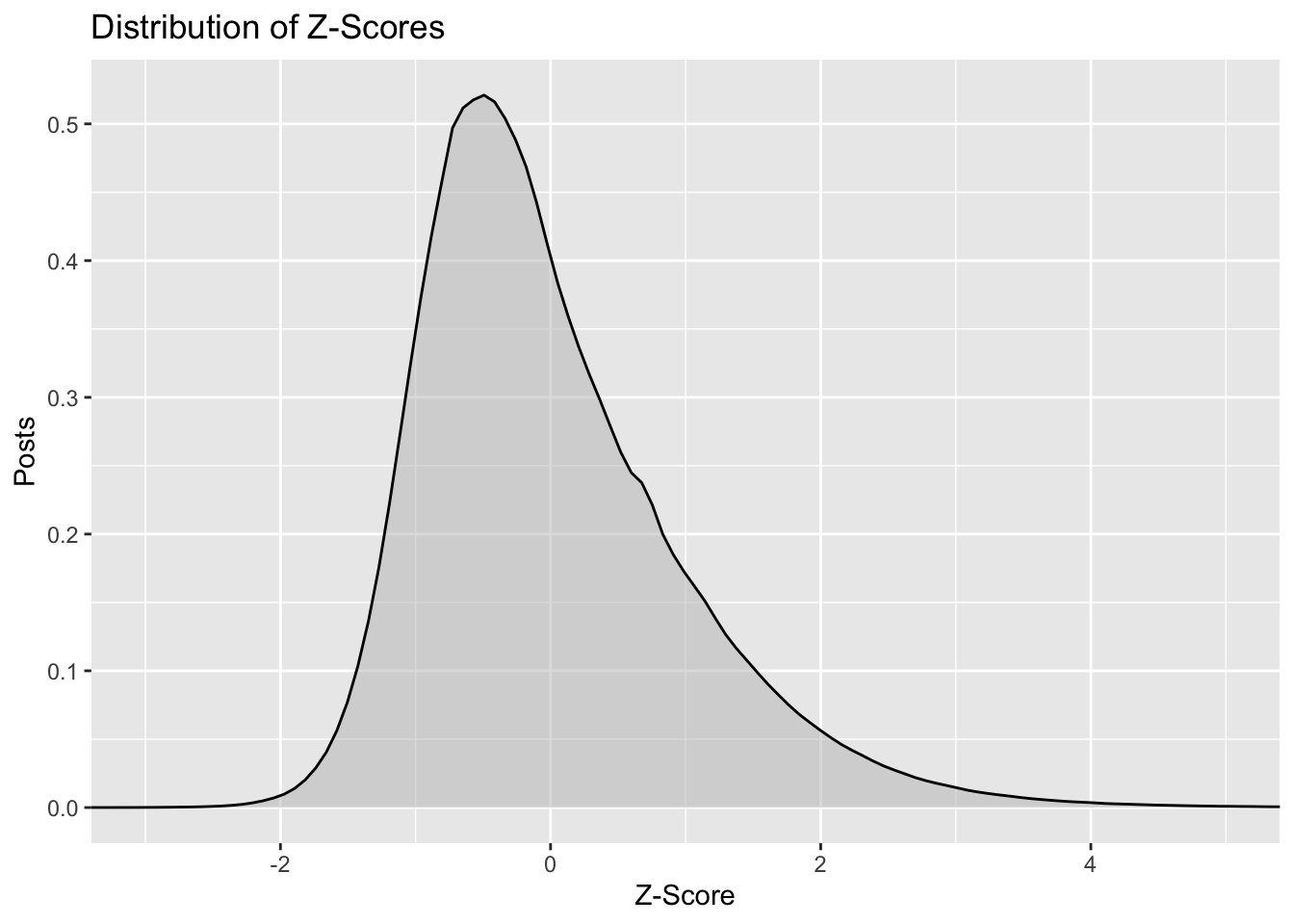
We can plot the distribution of z scores. This distribution is better suited to calculating summary statistics.
Code
# plot distribution of the z-scoresz_scores %>%ggplot(aes(x = z_score)) +geom_density(alpha =0.5, fill ="grey") +coord_cartesian(xlim =c(-3, 5)) +labs(x ="Z-Score", y ="Posts",title ="Distribution of Z-Scores")
Finding Best Posting Times with Z-Scores
Now let’s calculate some summary statistics. We’ll follow this approach:
For each profile-hour combination, calculate the median z_score. We’ll call this normalized_eng_rate.
For each hour-day combination, calculate the median normalized_eng_rate.
Plot this metric across all hours.
Code
# summary stats for z-scoresz_scores %>%filter(!is.na(z_score) &!is.na(local_time)) %>%mutate(hour_of_day =hour(local_time),day_of_week =wday(local_time)) %>%group_by(profile_id, day_of_week, hour_of_day) %>%summarise(posts =n_distinct(update_id), med_z_score =median(z_score)) %>%filter(posts >=5) %>%# make sure there are at least 5 posts in that time slotgroup_by(day_of_week, hour_of_day) %>%summarise(profiles =n_distinct(profile_id),med_z_score =median(med_z_score)) %>%filter(profiles >500) %>%# make sure there are enough profilesarrange(desc(med_z_score)) %>%head(10)
These hours are what we would suggest as posting times to try for Instagram.
Closing Thoughts
By normalizing each post’s performance against its baseline, we can make more meaningful comparisons across profiles with vastly different audience sizes and engagement patterns.
This approach is an attempt to answer the more useful question: “When does posting typically help individual creators perform better than usual?” instead of “When do the highest-engagement accounts tend to post?”
My hope is that this methodology is more useful for Buffer’s diverse user base, which ranges from individual creators to large brands with very different engagement patterns.
In the future, I’ll aim to add more factors such as post type, timezone, and user type to this data. Thank you for reading!