In this post we’ll look at the relationship between Buffer’s new posting streaks feature and engagement, where engagement is loosely defined as the number of interactions on a given social media post.
Data Collection
The first thing we’ll need is a SQL query that includes Buffer organizations that have been active in the last 90 days, their current streaks, the total number of posts they’ve created, and the total number of engagements that those posts have gotten.
Code
# write sql querysql <-" with orgs as ( select distinct p.organization_id , count(distinct p.id) as posts , sum(up.engagements) as total_engagements from dbt_buffer.segment_post_sent as p inner join dbt_buffer.publish_updates as up on p.post_id = up.id and up.engagements is not null where p.timestamp > timestamp_sub(current_timestamp, interval 90 day) group by 1 ) , streaks as ( select s.organization_id , s.count as current_streak from dbt_buffer.core_organization_streaks as s ) select distinct o.organization_id , o.posts , o.total_engagements , coalesce(s.current_streak, 0) as streak from orgs as o left join streaks as s on o.organization_id = s.organization_id"# get data from BigQueryorgs <-bq_query(sql = sql)
This returns approximately 118K organizations that have created posts (and have received engagements on those posts) in the past three months. We can use the skimr package to get a sense of what the data looks like.
Code
# skim dataskim(orgs)
Data summary
Name
orgs
Number of rows
117933
Number of columns
4
_______________________
Column type frequency:
character
1
numeric
3
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
organization_id
0
1
24
24
0
117933
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
posts
0
1
26.68
75.47
1
3
11
29
8644
▇▁▁▁▁
total_engagements
0
1
1722.52
43593.10
0
0
16
193
7809850
▇▁▁▁▁
streak
0
1
6.91
6.91
0
1
4
13
19
▇▂▂▁▃
In the hist column we can see that the data appears to be skewed, which isn’t uncommon and usually follows some sort of power-law distribution.
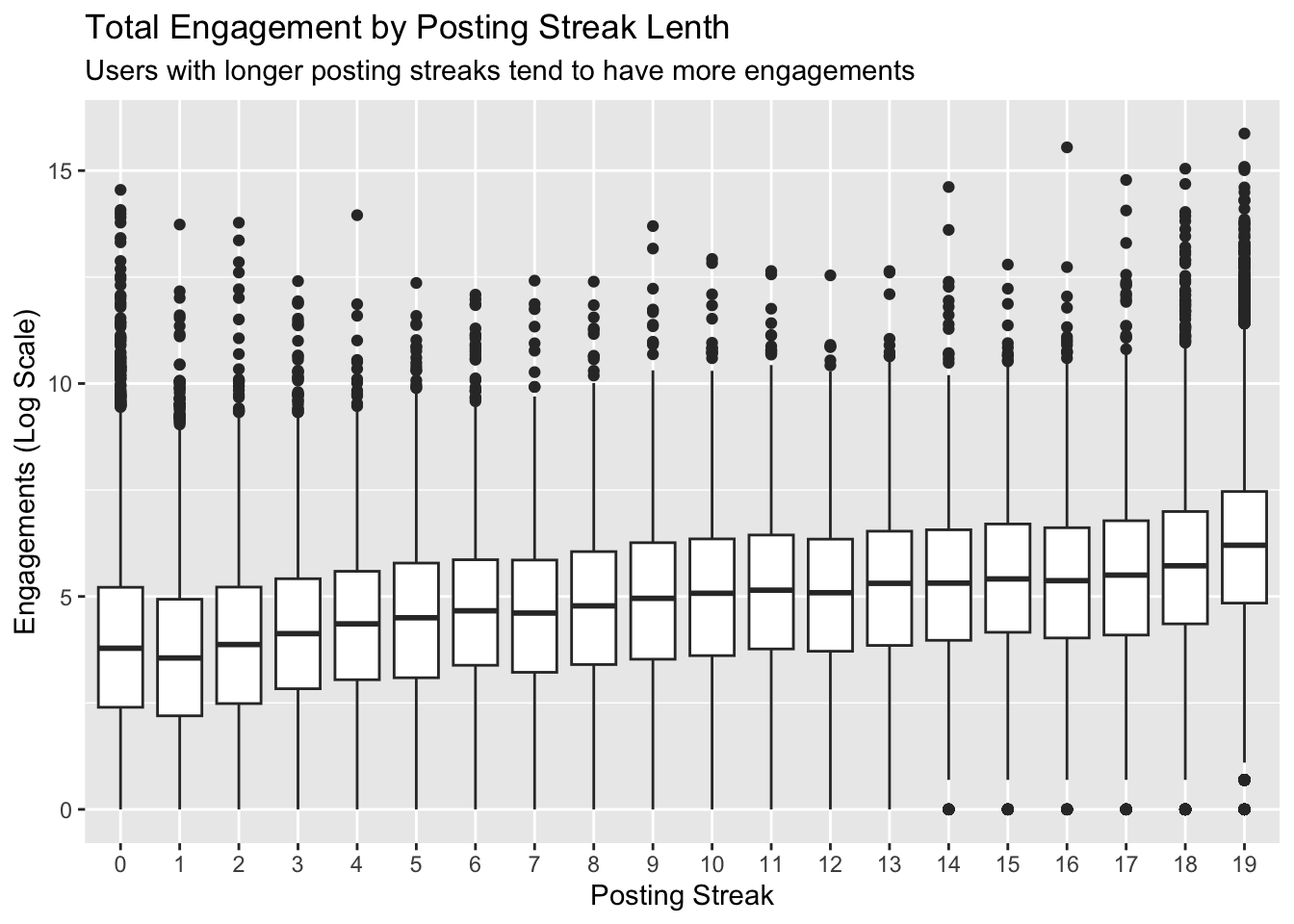
Let’s try visualizing the relationship between users’ streaks and the total number of engagements. Afterwards we’ll look at average engagement per post.
Because the engagement data is so skewed, we’ll apply a log transformation to help make the visualization easier to understand
Code
# plot streaks and total engagementorgs %>%filter(total_engagements >0) %>%ggplot(aes(x =factor(streak), y =log(total_engagements))) +geom_boxplot() +labs(x ="Posting Streak", y ="Engagements (Log Scale)",title ="Total Engagement by Posting Streak Lenth",subtitle ="Users with longer posting streaks tend to have more engagements")
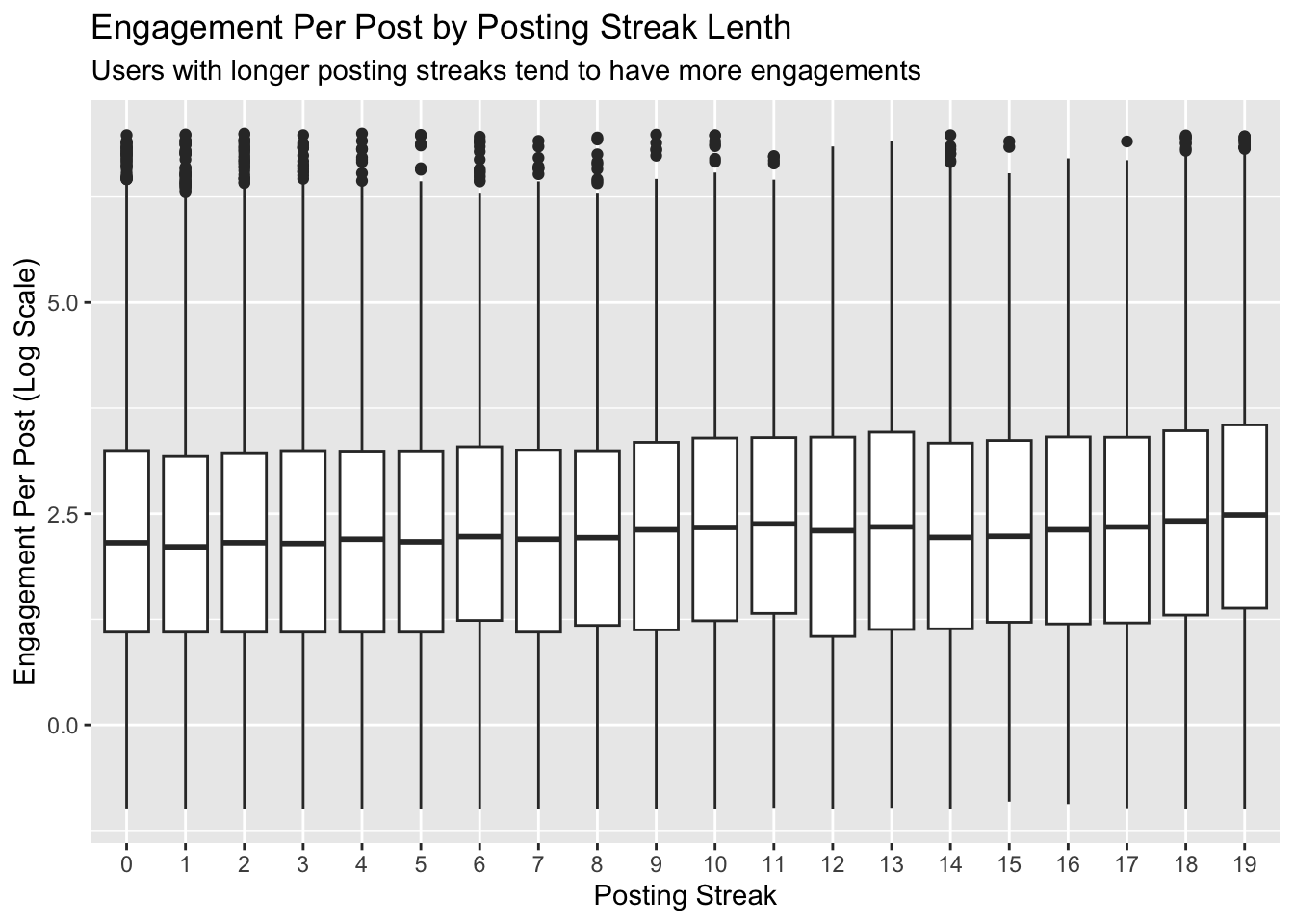
Now let’s plot the average number of engagements per post for users with different streak lengths.
Code
# plot streaks and average engagementorgs %>%filter(total_engagements >0) %>%mutate(avg_engagement = total_engagements / posts) %>%ggplot(aes(x =factor(streak), y =log(avg_engagement))) +geom_boxplot() +scale_y_continuous(limits =c(-1, 7)) +labs(x ="Posting Streak", y ="Engagement Per Post (Log Scale)",title ="Engagement Per Post by Posting Streak Lenth",subtitle ="Users with longer posting streaks tend to have more engagements")
Next let’s fit a linear regression model with a log transformation to try to quantify the effect that streak length might have on average engagement.
Code
# calculate average engagement per postorgs <- orgs %>%filter(total_engagements >0) %>%mutate(avg_engagement = total_engagements / posts)# fit linear model with log transformationmodel_log <-lm(log(avg_engagement +1) ~ streak, data = orgs)# summarize modelsummary(model_log)
Call:
lm(formula = log(avg_engagement + 1) ~ streak, data = orgs)
Residuals:
Min 1Q Median 3Q Max
-2.5188 -1.1364 -0.1315 0.9267 9.4488
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.2760801 0.0081425 279.5 <2e-16 ***
streak 0.0130037 0.0007345 17.7 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.48 on 73616 degrees of freedom
Multiple R-squared: 0.00424, Adjusted R-squared: 0.004226
F-statistic: 313.4 on 1 and 73616 DF, p-value: < 2.2e-16
Overall, the model suggests that longer posting streaks are associated with modestly higher engagement levels. Each additional streak unit predicts approximately 1.31% more engagement per post. However, the low R-squared indicates that streak length alone explains only a small portion of the variation in engagement, which makes sense.